
 场外配资平台
场外配资平台
来自南京大学 PRLab 的魏佳哲、李垦,在准聘助理教授司晨阳的指导下,提出专业级海报设计与编辑大模型 PosterCopilot。本研究联合了 LibLib.ai、中国科学院自动化研究所等多家顶尖机构,共同完成了首个解耦布局推理与多轮可控编辑的图形设计框架研发。PosterCopilot 能够实现专业设计级的版式生成、语义一致的多轮编辑,并具备高度可控的创作能力。

此外,受华为-南京大学鲲鹏昇腾科教创新孵化中心支持,该模型已完成对国产昇腾算力平台的适配与部署,进一步推动了国产 AI 设计技术的发展与落地。

论文标题: Poster Copilot: Toward Layout Reasoning and Controllable Editing for Professional Graphic Design
论文地址:https://arxiv.org/abs/2512.04082
项目主页:https://postercopilot.github.io/
行业痛点:
从生成式失控到多模态「盲推」
平面设计是视觉传达的基石,但要实现真正的自动化专业设计,目前仍面临巨大挑战。尽管以 Stable Diffusion 为代表的文生图(T2I)模型在图像合成上表现强劲,但在实际的工业设计流中,它们因无法处理分层结构,往往导致用户素材失真且无法进行精细化控制。
为了解决这一问题,业界开始尝试利用多模态大模型(LMMs)进行布局规划,然而研究团队发现,现有的 LMMs 方案反而暴露出了四大致命短板:
几何布局的「先天缺陷」: 现有的多模态布局模型通常将连续的空间坐标量化为离散的文本 Token。这种将数值视为文本的处理方式,从根本上破坏了欧几里得空间的几何连续性,导致模型难以理解真实的物理距离与空间关系,生成的布局频频出现对齐错误与比例失调。
视觉反馈的「盲区」: 这是现有模型最严重的缺失之一。目前的布局模型在训练过程中仅进行纯粹的坐标回归,却从未「看」到过布局渲染后的实际图像。由于缺乏对渲染结果的视觉反馈(Visual Feedback),模型无法像人类设计师一样基于审美直觉和视觉规律来审视并优化构图,只能处于「盲人摸象」的状态。
单一真值的「回归陷阱」: 海报设计属于高度主观的创意领域,符合人类审美的布局方案往往是多样的、非唯一的。然而,传统的监督训练强迫模型死板地向单一的 Ground Truth 回归。这种刻板的训练方式不仅导致生成的布局丧失多样性,更扼杀了模型的探索潜力,使其错失了涌现超越训练数据、比原始真值更具美学表现力的创新设计的机会。
图层级编辑的「断层」: 专业设计师的工作流本质上是迭代的(Iterative),需要对特定图层进行反复微调。而目前的端到端模型往往是「一锤子买卖」,面对「只改一个图层」的需求时往往束手无策——要么无法支持,要么「牵一发而动全身」,在修改时破坏了用户原有的素材或非编辑区域。
在 PosterCopilot 的对比测试中,这些弱点暴露无遗:

现有模型在处理复杂多素材场景时,常出现严重的元素重叠、文字遮挡以及美学灾难。这反映了现有模型在细粒度布局推理和美学对齐上的根本不足。
同时,如图所示:

基于完全相同的元素可以有众多符合人类审美的布局方案,按照单一真值进行回归的训练方式容易扼杀模型的创造力。
核心成果:
构建专业级设计的「智能工作流」
为填补现有单步生成与专业工作流之间的鸿沟,研究团队提出了一套系统性的解决方案 PosterCopilot,并通过渐进式三阶段训练策略赋予模型设计推理能力。
独创三阶段训练:从几何纠偏到美学对齐
这是首个将布局生成任务从简单的回归问题转化为分布学习与强化学习结合的范式。
阶段一:扰动监督微调(PSFT): 针对 Token 坐标导致的几何空间扭曲问题,团队提出引入高斯噪声扰动,迫使模型学习坐标的分布而非死记硬背离散点,修复了优化空间的几何结构。
阶段二:视觉-现实对齐强化学习(RL-VRA): 引入基于 DIoU 和元素保真的验证性奖励信号,专门修正「幻觉」导致的重叠和比例失调。
阶段三:美学反馈强化学习(RLAF): 利用美学奖励模型进行偏好对齐,鼓励模型探索超出 Ground Truth 但更具视觉冲击力的布局方案。

生成式智能体(Generative Agent):打通迭代编辑闭环
PosterCopilot 不仅仅是一个布局生成器,更是一个全能设计助手。团队设计了一个包含「接待模型」和「T2I 模型」的智能体,支持从灵感到素材的无缝转化:用户仅需输入抽象的设计构思,内置的接待模型(Reception Model)即可充当「创意策划」,自动将用户意图拆解为前景主体与背景氛围的详细规划。
随后,模型会生成精准的工程级提示词(Prompts),驱动 T2I 模型即时生成风格契合的高质量素材,实现从「抽象灵感」到「具体物料」的自动化落地。
通过将具备精密布局推理能力的设计模型与支持多轮交互的生成式智能体(Generative Agent)深度耦合,团队构建了 PosterCopilot 的完整框架,其从素材规划到最终成稿的推理流水线如下所示:
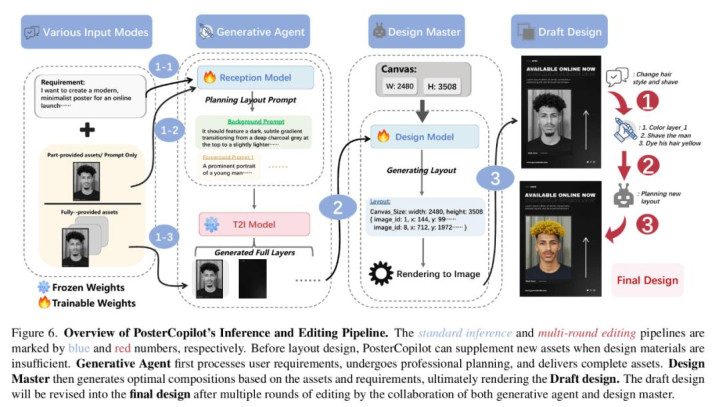
全能设计助手 PosterCopilot:覆盖专业设计的全链路需求
基于 Generative Agent 的强大赋能,PosterCopilot 能够完美胜任从「从零构建」到「后期精修」的多种专业场景:
全素材海报生成(Generation from Fully-provided Assets): 当用户提供完整素材时,模型专注于「布局推理」,能够将多模态元素在画布上进行符合美学规律的精准排列,同时严格保障用户原有素材零失真、无篡改。

缺素材智能补全(Generation from Insufficient Assets): 针对素材缺失的冷启动场景,智能体能够理解设计意图,自动生成风格统一的背景或前景装饰层,实现从「抽象想法」到「完整海报」的无缝落地。

多轮精细化编辑(Multi-round Fine-grained Edit): 打破了传统模型「无法精准局部修改」的魔咒,支持多种专业级操作:

全局主题迁移: 能够将海报从「棒棒糖促销」无缝切换为「冰淇淋推广」,自动替换主体并调整相关元素,且保留原有排版骨架。

智能尺寸重构(Poster Reframe): 只需更改画布尺寸参数,模型即可根据新的长宽比,智能重新推理布局,实现一键适配不同媒体版面。

PosterCopilot 数据集:高质量分层海报库
为解决数据匮乏问题,团队构建了包含 16 万张专业海报、总计 260 万个图层的高质量数据集。通过 OCR 辅助的细粒度图层融合技术,解决了传统数据集中图层过度碎片化(Over-segmentation)的难题,为社区提供了宝贵的数据资源。

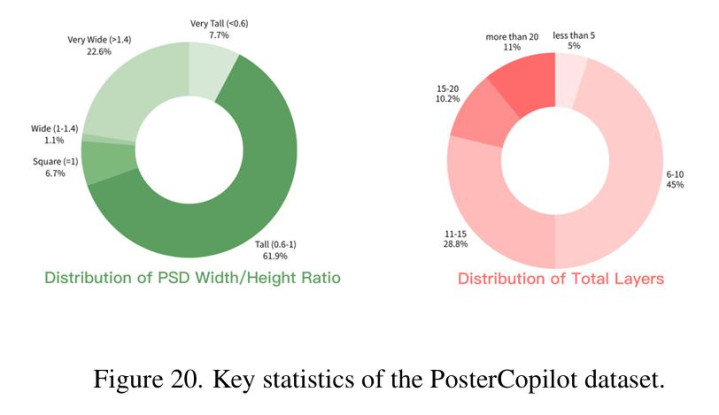
实验结果:
全面超越商业竞品与 SOTA 模型
PosterCopilot 以 Qwen-2.5-VL-7B-Instruct 为 backbone,在多项指标上实现了对现有顶尖模型的超越。
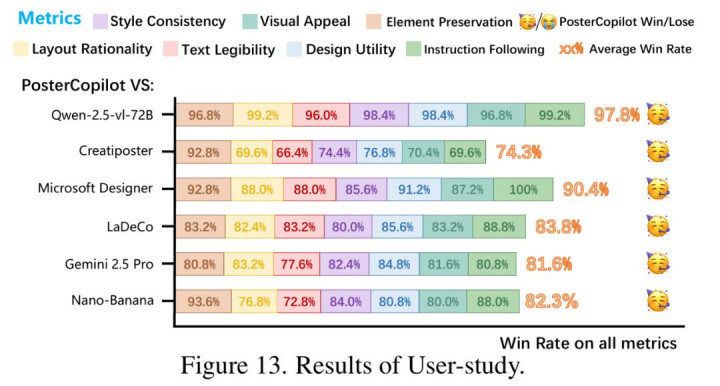
在涵盖布局合理性、文本可读性、素材保真度等六大维度的评测中,PosterCopilot 展现了统治级表现。
综合胜率: 在人工评测中,PosterCopilot 对比微软 Microsoft Designer、Nano-Banana 以及学术界 SOTA(如 CreatiPoster、LaDeCo),平均胜率超过 74%。
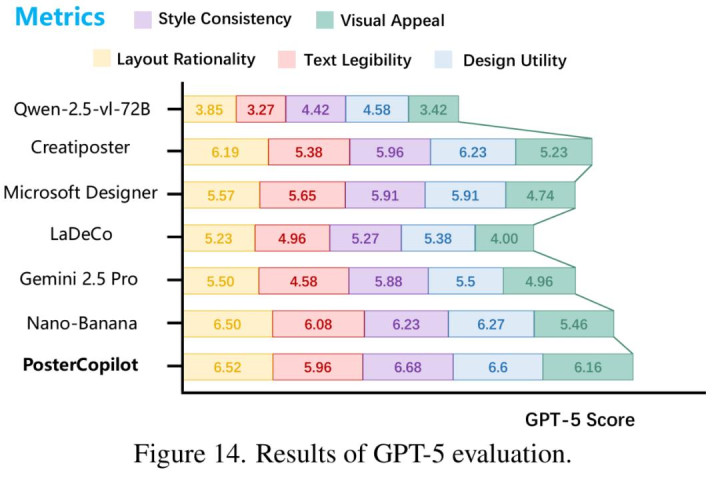
GPT-5 评测: 在 GPT-5 的打分中,PosterCopilot 在布局合理性(Layout Rationality)和风格一致性(Style Consistency)上均大幅领先 Qwen-VL-2.5-72B 和 Gemini 2.5 Pro。
结论与展望
对于平面设计这样兼具严谨几何约束与感性美学追求的领域,简单的端到端生成并非最优解。
PosterCopilot 通过解耦「布局推理」与「生成式编辑」,并引入强化学习对齐人类美学,成功让大模型掌握了专业设计师的「图层思维」。这不仅为智能设计工具树立了新的基准场外配资平台,也为未来 AI 辅助创意工作流提供了新的范式。
保利配资提示:文章来自网络,不代表本站观点。
- 上一篇:场外配资平台 水泥网报告:印度推出铁路新政,促进散装水泥消费占比提升
- 下一篇:没有了
相关文章


沪深京指数
热点资讯



